💡 We introduce PaW that co-trains policy and world modeling inside RL reusing rollouts. Read paper here!

Ning Lu (卢宁)
I am currently pursuing a Ph.D. in CSE at Hong Kong University of Science and Technology (HKUST), where I focus on the Safety of Language Models. Previously I was an intern researcher at Bytedance-Seed, where I focus on the Agentic Reinforcement Learning. Now I am focusing on Agentic Reinforcement Learning and World Modeling for LLM.
Research Interest:
- LLM RL for Agent and Reasoning: PaW, HIVE, AHDAgent, Is PRM Necessary?
- LLM Alignment & RedTeaming: SafeDelta, SICO
I expect to graduate in 2026 and am actively seeking industry positions. Please feel free to reach out via email at nluab AT cse.ust.hk !
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Hong Kong University of Science and TechnologyPhD in Computer Science and EngineeringSep. 2021 - Present
Hong Kong University of Science and TechnologyPhD in Computer Science and EngineeringSep. 2021 - Present -
 Southern University of Science and TechnologyRanked 916th in Shandong Province Gaokao
Southern University of Science and TechnologyRanked 916th in Shandong Province Gaokao
BSc in Computer Science and EngineeringSep. 2016 - Jul. 2020
Experience
-
 ByteDance, SeedSep. 2025 - Mar. 2026• Contributed to the development of Doubao Voice Agent.
ByteDance, SeedSep. 2025 - Mar. 2026• Contributed to the development of Doubao Voice Agent.
• Contributed to the Seed-2.0-lite-0428 RLVR post-training. -
ByteDance, Data-DouyinApr. 2025 - Aug. 2025Research Intern, focusing on LLM RL.
-
 Huawei, 2012 LabJune 2024 - Oct. 2024Research Intern, focusing on fault-torlerant large language model pre-training
Huawei, 2012 LabJune 2024 - Oct. 2024Research Intern, focusing on fault-torlerant large language model pre-training
Honors & Awards
-
Outstanding Entrance Scholarship2016
-
Outstanding Graduate of the Computer Science Department2020
News
2026
We introduce AHD Agent, the first LLM agent framework for automatic algorithm design. Read paper here!
Excited to share that Seed-2.0-lite-0428, a project I contributed to, is now released — achieving Gemini-level multimodal understanding.
We propose HIVE, which acclerates the LLM RL training by prompt-entropy-based data selection. Read paper here!
2025
Is Process Reward Model (PRM) Really Necessary? Check out my new paper analyzing the role of PRMs in reasoning tasks. Accepted in NeurIPS 2025. Read paper here!
My paper was accepted to ICML 2025! We propose Safe Delta, a method that preserves safety when fine-tuning LLMs on diverse datasets. Read paper here!
My paper was accepted to ICDE 2025! It’s the first to propose a backdoor attack in graph data condensation.
Selected Publications (view all )
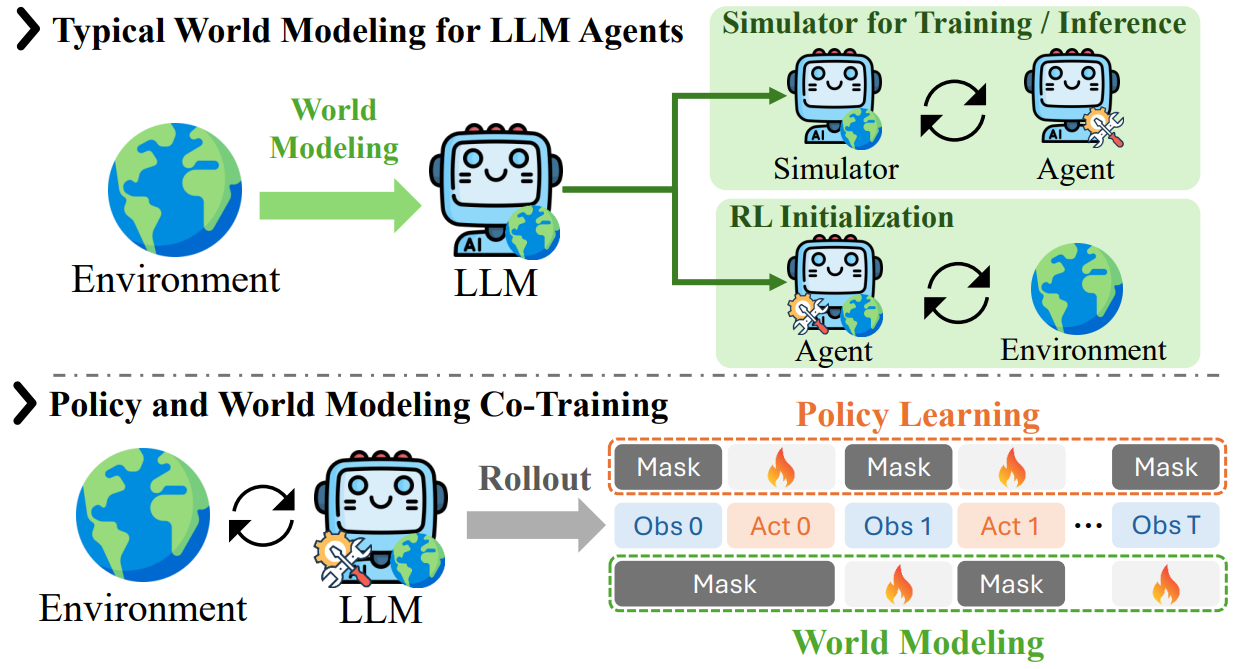
Policy and World Modeling Co-Training for Language Agents
Ning Lu*, Baijiong Lin*, Shengcai Liu, Jiahao Wu, Haoze Lv, Yanbin Wei, Lingting Zhu, Shengju Qian, Xin Wang, Ying-Cong Chen, Qi Wang, Ke Tang (* equal contribution)
Under review. 2026
The first policy and world-modeling co-training RL framework for LLM agents.
Policy and World Modeling Co-Training for Language Agents
Ning Lu*, Baijiong Lin*, Shengcai Liu, Jiahao Wu, Haoze Lv, Yanbin Wei, Lingting Zhu, Shengju Qian, Xin Wang, Ying-Cong Chen, Qi Wang, Ke Tang (* equal contribution)
Under review. 2026
The first policy and world-modeling co-training RL framework for LLM agents.
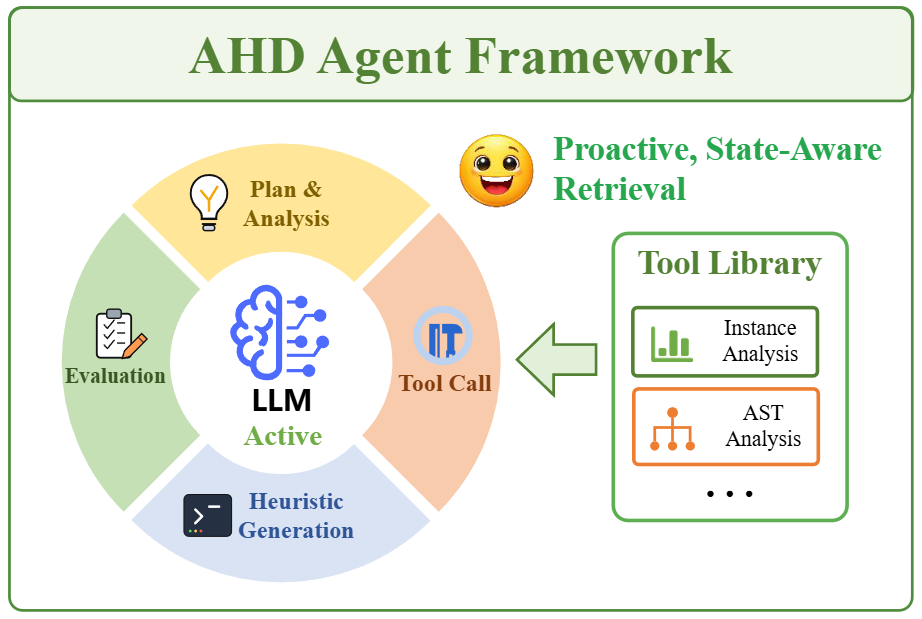
AHD Agent: Agentic Reinforcement Learning for Automatic Heuristic Design
Haoze Lv*, Ning Lu*, Ziang Zhou, Shengcai Liu (* equal contribution)
Under review. 2026
The first tool-integrated multi-turn agentic framework for automatic algorithm design.
AHD Agent: Agentic Reinforcement Learning for Automatic Heuristic Design
Haoze Lv*, Ning Lu*, Ziang Zhou, Shengcai Liu (* equal contribution)
Under review. 2026
The first tool-integrated multi-turn agentic framework for automatic algorithm design.
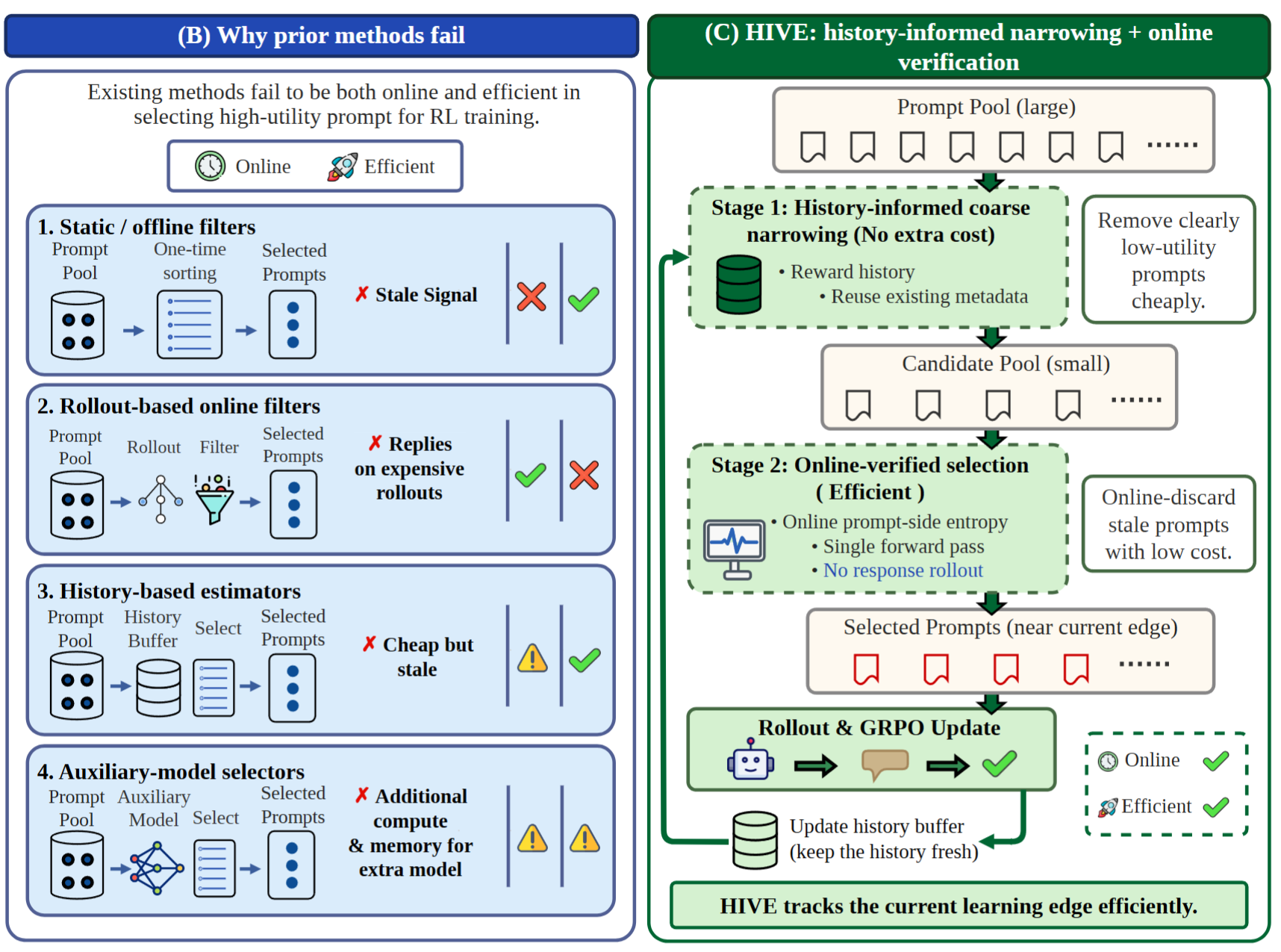
Train at the Moving Edge: Efficient RL for Large Reasoning Models via Rollout Selection
Jiahao Wu*, Ning Lu*, Shengcai Liu, Kun Wang, Yanting Yang, Li Qing, Ke Tang (* equal contribution)
Under review. 2026
The first online policy-verified data selection framework for efficient RL training.
Train at the Moving Edge: Efficient RL for Large Reasoning Models via Rollout Selection
Jiahao Wu*, Ning Lu*, Shengcai Liu, Kun Wang, Yanting Yang, Li Qing, Ke Tang (* equal contribution)
Under review. 2026
The first online policy-verified data selection framework for efficient RL training.
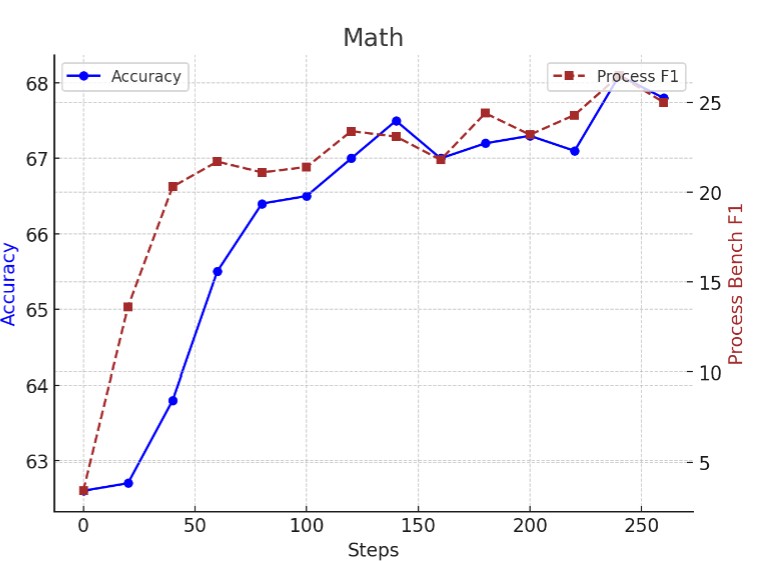
Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs
Zhangying Feng*, Qianglong Chen*, Ning Lu, Yongqian Li, Siqi Cheng, Shuangmu Peng, Duyu Tang, Shengcai Liu, Zhirui Zhang (* equal contribution)
Conference on Neural Information Processing Systems (NeurIPS) 2025
Unifying problem solving and solution-process judgment.
Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs
Zhangying Feng*, Qianglong Chen*, Ning Lu, Yongqian Li, Siqi Cheng, Shuangmu Peng, Duyu Tang, Shengcai Liu, Zhirui Zhang (* equal contribution)
Conference on Neural Information Processing Systems (NeurIPS) 2025
Unifying problem solving and solution-process judgment.
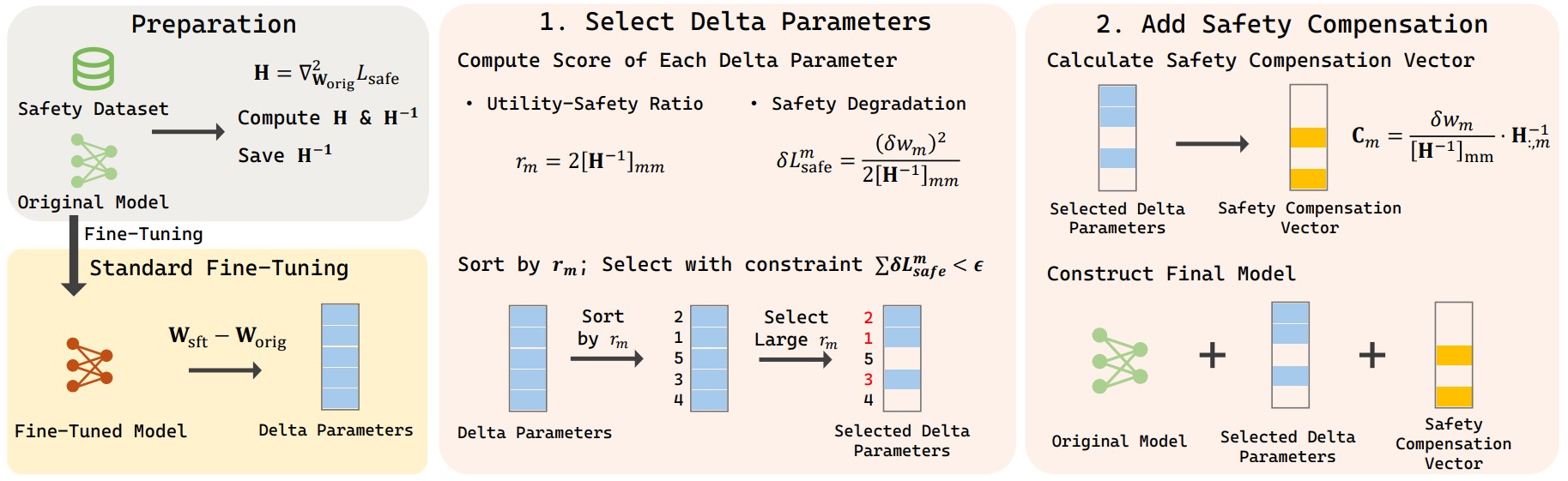
Safe Delta: Consistently Preserving Safety when Fine-Tuning LLMs on Diverse Datasets
Ning Lu, Shengcai Liu, Jiahao Wu, Weiyu Chen, Zhirui Zhang, Yew-Soon Ong, Qi Wang, Ke Tang
International Conference on Machine Learning (ICML) 2025
The first safety-aware post-fine-tuning defense method for LLM alignment.
Safe Delta: Consistently Preserving Safety when Fine-Tuning LLMs on Diverse Datasets
Ning Lu, Shengcai Liu, Jiahao Wu, Weiyu Chen, Zhirui Zhang, Yew-Soon Ong, Qi Wang, Ke Tang
International Conference on Machine Learning (ICML) 2025
The first safety-aware post-fine-tuning defense method for LLM alignment.